If there is one thing a lay man needs to know about digital cameras, its that per pixel in the camera, the color captured by a certain digital color camera is the integral of the product of the spectral power distribution of the incident light source  , the surface reflectance
, the surface reflectance  and the spectral sensitivity of the camera
and the spectral sensitivity of the camera 
 , the surface reflectance
, the surface reflectance  and the spectral sensitivity of the camera
and the spectral sensitivity of the camera 

and where




Figure 1: 'Auto' White Balance Setting (left image). The image in the middle is the result of implementing the White Patch Algorithm. The image on the right is the result of implementing the Gray World Algorithm.



Figure 2: 'Daylight' White Balance Setting (left image). The image in the middle is the result of implementing the White Patch Algorithm. The image on the right is the result of implementing the Gray World Algorithm.



Figure 3: 'Fluorescent' White Balance Setting (left image). The image in the middle is the result of implementing the White Patch Algorithm. The image on the right is the result of implementing the Gray World Algorithm.



Figure 4: 'Tungsten' White Balance Setting (left image). The image in the middle is the result of implementing the White Patch Algorithm. The image on the right is the result of implementing the Gray World Algorithm.



Figure 5: Objects of the same hue (color) under 'Fluorescent' white balance setting. Left image is the unprocessed image captured under 'Fluorescent' white balance setting. Middle image is the result after applying the white patch algorithm. Rightmost image is the result after applying the gray world algorithm.

, i = [Red, Green and Blue]. K is the balancing constant equal to the inverse of the camera output when a white object is shown.
Digital Cameras nowadays have the White Balance feature wherein the user can adjust the white balancing constants appropriate for certain conditions. White balancing simply implies that when a camera captures an image, white will (and should) appear white in the captured image. The following are some of the settings a user can set the White Balance to
- Sun - for sunny and bright outdoors
- Cloud - for a cloudy day
- Light Bulb - for incandescent lighting
- Fluorescent lamp - for fluorescent lighting
If setting the proper White Balance becomes quite tedious, the 'AWB' setting, which stands for Automatic White Balancing, can instead be used. Other symbols such as the '6500K' can also be seen, this stands for the color temperature of the light. Again, the reason as to why setting the white balance to its proper condition is recommended to make white appear white with the rest of the colors properly rendered.
There are two well known algorithms that can perform automatic white balancing, the White Patch Algorithm and the Gray World Algorithm. The key idea in Automatic White Balancing is to determine the output of the camera for a white object. In white patch algorithm, an image is taken under a wrongly white balanced setting, then use the RGB values of a known white object as the divider (divide this to the obtained R,G,B of the image). On the other hand, Gray world algorithm, assumes that the average color of the world is gray, hence take the average of the R,G and B of the wrongly white balanced image and use this average r,g and b value as the divider (divide this to the obtained R,G and B of the image).
The following figures are the result of implementing the Automatic White Balancing algorithms on several wrongly white balanced images.



Figure 1: 'Auto' White Balance Setting (left image). The image in the middle is the result of implementing the White Patch Algorithm. The image on the right is the result of implementing the Gray World Algorithm.



Figure 2: 'Daylight' White Balance Setting (left image). The image in the middle is the result of implementing the White Patch Algorithm. The image on the right is the result of implementing the Gray World Algorithm.



Figure 3: 'Fluorescent' White Balance Setting (left image). The image in the middle is the result of implementing the White Patch Algorithm. The image on the right is the result of implementing the Gray World Algorithm.



Figure 4: 'Tungsten' White Balance Setting (left image). The image in the middle is the result of implementing the White Patch Algorithm. The image on the right is the result of implementing the Gray World Algorithm.
Before I proceed, I would like to thank May Ann Tenorio for the images in figures 1 to 4 (unprocessed images).
It can be observed that whether the White Patch algorithm or the Gray World Algorithm, is used white did indeed appear white. Using the gray world algorithm though supersaturates the image (the image became very bright) relative to the image produced when the white patch algorithm is used. For this case, it is better to implement the white patch algorithm instead of the gray world algorithm.



Figure 5: Objects of the same hue (color) under 'Fluorescent' white balance setting. Left image is the unprocessed image captured under 'Fluorescent' white balance setting. Middle image is the result after applying the white patch algorithm. Rightmost image is the result after applying the gray world algorithm.
Before I proceed, I would like to thank Aivin Solatorio for the image (unprocessed).
--
Technical Correctness: 5/5
Quality of Presentation: 5/5
Figure 5 shows an image of objects of the same hue (color) captured under 'Fluorescent' white balance setting. It can be observed that using the white patch algorithm is so much better in 'white balancing' the image compared to using the gray world algorithm wherein parts of the images are again supersaturated. So all in all, it is recommended to use the White Patch Algorithm rather than the Gray world algorithm in the Auto White Balance feature of any camera.
Again, I would like to thank May Ann Tenorio and Aivin Solatorio for the images. I would also like to acknowledge my discussions with Tino Borja, Arvin Mabilangan, Gino Leynes and Dr. Soriano.
--
Technical Correctness: 5/5
Quality of Presentation: 5/5












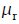













































{kind=link}
{kind=link}